What is Transformer Model? How does it work?

The Transformer Model is a novel architecture that aims to solve sequence-to-sequence while handling long-range dependencies with ease. It is the current state-of-the-art technique in the field of NLP.
Transformer-based models have primarily replaced LSTM, and it has been proved to be superior in quality for many sequence-to-sequence problems. Transformer lends itself to parallelization and also it utilized that GPU can be effective. GoogleCloud’s recommendation to use the transformer as a reference model to use their cloud TPU.
Let's see a detailed explanation of the Transformer Model.
Before directly jumping into the transformer, first know about RNN & LSTM.
Problem with RNN based Encoder-Decoder
However, RNN models have some problems, they are slow to train, and they can’t deal with long sequences.
They take input sequentially one by one, which is not able to use up GPU’s very well, which are designed for parallel computation.
RNNs also can’t deal with long sequences very well as we get vanishing and exploding gradients if the input sequence is too long. Generally, you will see NaN (Not a Number) in the loss during the training process. These are also known as the long-term dependency problems in RNNs.
Long Short Term Memory- Special kind of RNN especially made for solving vanishing gradient problems. They are capable of learning Long-Term Dependencies. Remembering information for long periods of time is practically their default behavior, not something they struggle to learn!
The LSTM neurons have unlike normal neurons have a branch that allows to pass information and to skip the long processing of the current cell this allows the memory to be retained for a longer period of time. It does improve the situation of the Vanishing Gradient Problem but not that amazing like it will do good till 100 words, but for like 1000 words it starts to lose its grip.

Certainly, LSTMs have improved memory, able to deal with longer sequences than RNNs. However, LSTM networks are even slower as they are more complex.
In RNN based sequence-to-sequence model, in the below diagram,

both encoders and decoders are RNN, at every time step in the encoder, the RNN takes a word vector X1 from the input sequence and a hidden state H1 from the previous time step. In each time step, RNN updates its hidden state based on inputs and previous output it has seen. The hidden state from the last unit is known as Context Vector. This contains information about the input sequence.
The context vector turned out to be problematic for these types of models. The model has a problem while dealing with long-range dependencies and it facing a vanishing gradient problem in long sentences. To solve this problem, Attention was introduced. It highly improved the quality of machine translation as it allows the model to focus on the relevant part of the input sequence as needed.
The attention mechanism has increased encoder-decoder networks’ performance, but the bottleneck in speed is still due to RNN having to process word by word sequentially. Can we remove RNN for sequential data?
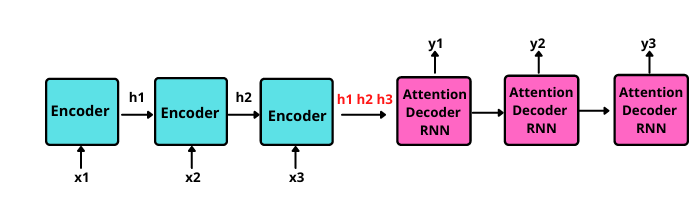
In the Attention Model, the encoder passes a lot more data and the final encoder passes all the hidden states(even the intermediate ones) to the decoder.
The decoder checks each hidden state that it received as every hidden state of the encoder is mostly associated with a particular word of the input sentence.
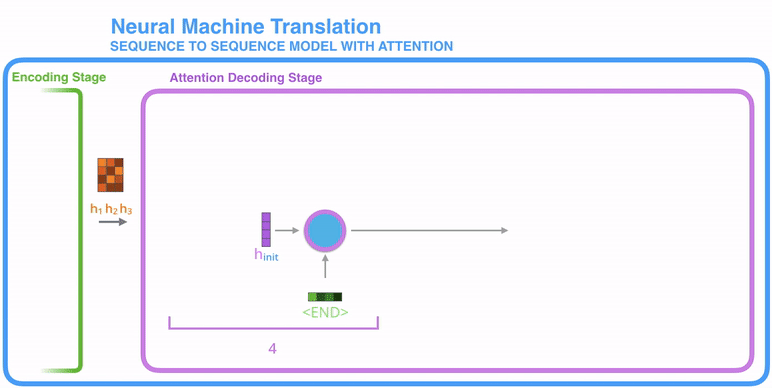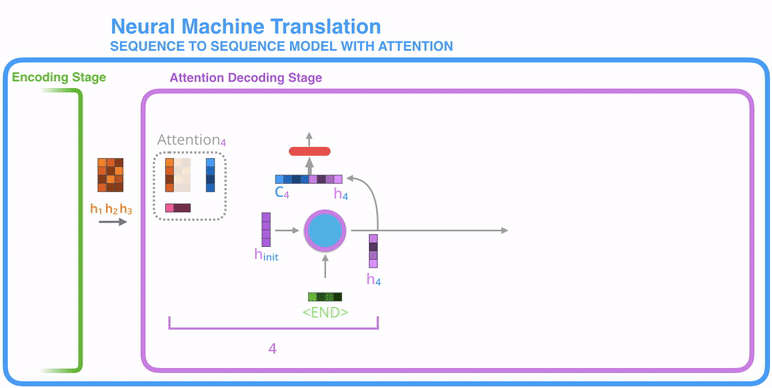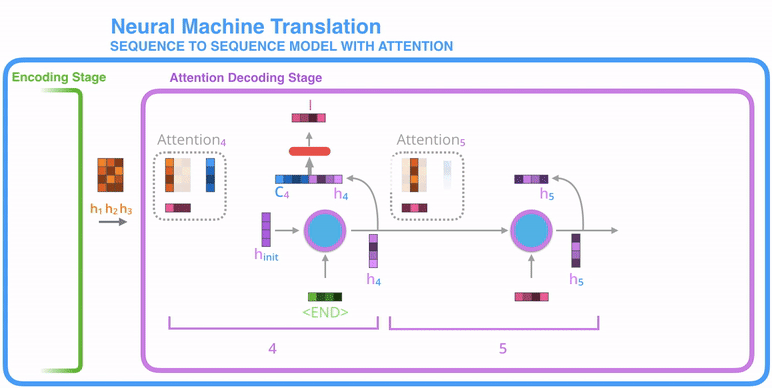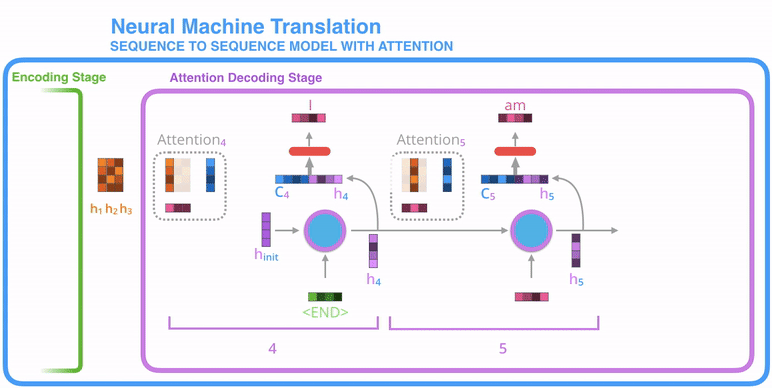
The attention decoder layer takes the embedding of the <END> token, and an initial decoder hidden state, the RNN processes its input and produces an output and a new hidden state vector (h4). Now we use encoder hidden states (h1 h2 h3) and (h4) vector to calculate a context vector (c4) for the time step.
This is where the attention concept is applied, that's why it's called the Attention Step.
Concatenate (h4) and (c4) in one vector. This vector passed into feed-forward neural networks indicates the output word of this time step. It repeated for next time steps.
So, this is how Attention works.
How can we use parallelization for sequential data?
Attention is all you need. The Transformer architecture was introduced in 2017. Like the encoder-decoder architectures, where input sequences are fed into the Encoder, and the Decoder will predict each word after another. The Transformer improves its time complexity and performance by eliminating RNN and utilizing the attention mechanism.
The architecture:
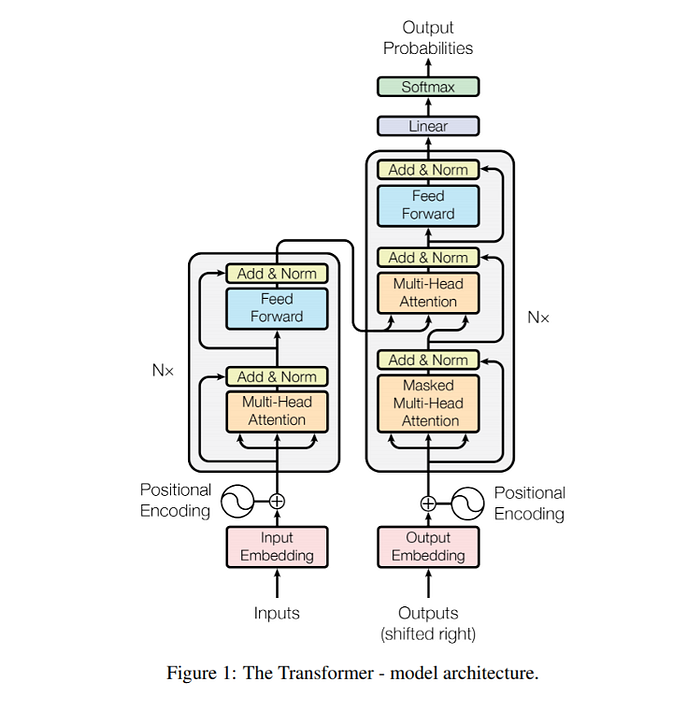
The Encoder Block:
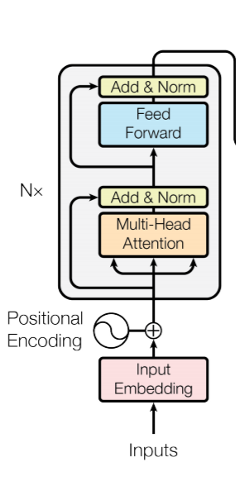
First, the input words need to convert to vectors. This can be possible using Embedding Space. It's like an open space of a dictionary where words of similar meanings are grouped together or are present close to each other in the space.
Every word, according to its meaning, is mapped and assigned with a particular value.
But there is one issue when convert words to vectors, every word in different sentences have a different meaning. Positional Encoders is to solve this issue.
It is a vector that gives context according to the position of the word in a sentence.
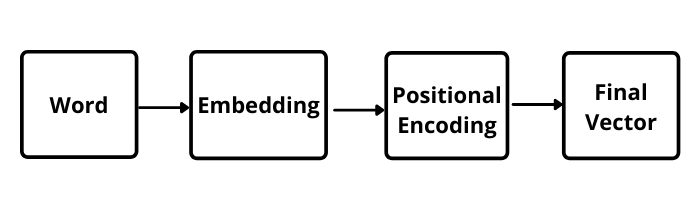
The final vector is pass to the Encoder Block. In Encoder Block, the first process is the Multi-Head Attention Layer.
First, we know about the self-attention,
We know that attention is a mechanism to find the words of importance for a given query word in a sentence. The mathematical representation for the attention mechanism looks like the figure given below:
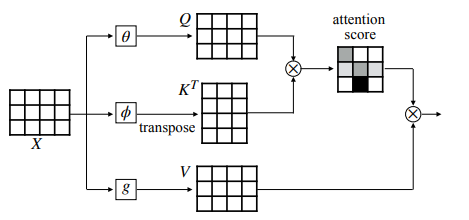
So, X is the input word sequence, and we calculate three values from that which are Q(Query), K(Key), and V(Value).
The task is to find the important words from the Keys for the Query word. This is done by passing the query and key to a mathematical function (usually matrix multiplication followed by softmax). The resulting context vector for Q is the multiplication of the probability vector obtained by the softmax with the Value.
When the Query, Key, and Value are all generated from the same input sequence X, it is called Self-Attention.
The generated vector for the given word is represented as an attention vector. This process is continued for every word in a sentence.
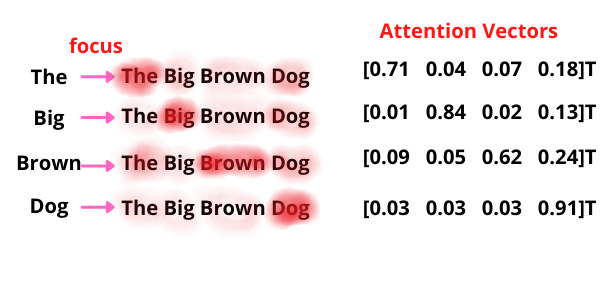
The only problem it focuses on is that for every word it weighs its value much higher or itself in the sentence, we are inclined towards its interaction with other words of that sentence. So, we determine multiple attention vectors per word and take a weighted average to compute the final attention vector of every word.

As we are using multiple attention vectors, it is called the Multi-Head Attention Layer.
Multi-Head Attention is a module for attention mechanisms that run through an attention mechanism several times in parallel. The independent attention outputs are then concatenated and linearly transformed into the expected dimension. Multiple Attention heads allow for attending to parts of the sequence differently.
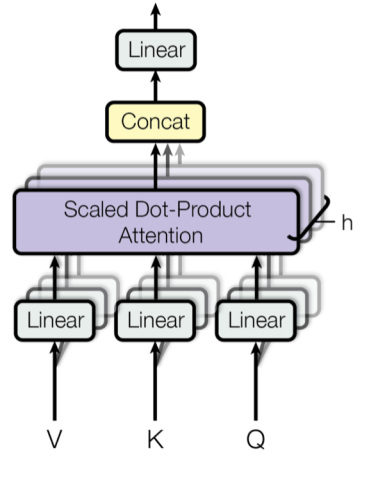
After the Multi-Head Attention Process, the next step is Feed Forward Neural Network.
It helps to every attention vector is transform to the form that is acceptable by the next encoder or decoder layer. It accepts the attention vector “One at a time”. Compared to RNN, these attention vectors are independent of each other. So, parallelization can be applied here, and that makes all the difference.
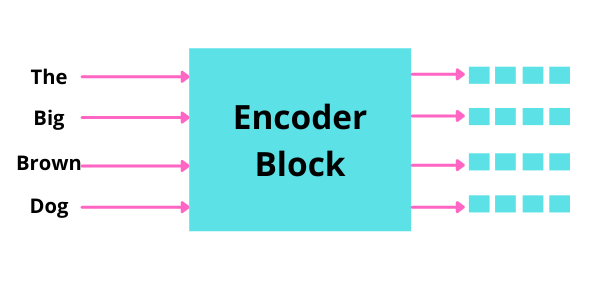
Now we can pass all the words at the same time into the encoder block, and get the set of encoded vectors for every word simultaneously.
The Decoder Block:
First, we have Embedding Layer and Positional Encoder part which changes the words into respective vectors. It is similar to what we have seen in the Encoder part.
One layer is different from the Encoder part, that called Masked-Multi Head attention part.
Consider the translation of English sentence to French Sentence.
Similar to the Multi-Head Attention in the Encoder Block. The Attention Block generates Attention vectors for every word in the French Sentence to represent how much each word is related to every word in the same output sentence.
Unlike the Attention Block in the Encoder that receiving every word in the English Sentence, only the previous words of the French Sentence are fed into this Decoder’s Attention Block. So while performing the parallelization with matrix operation we make sure that the matrix should mask the words appearing later by transforming them into 0’s so that the attention network cant use them.

Now resulting attention vector from the Encoder’s Multi-Head Attention and Decoder’s Masked Multi-Head Attention. That’s why it's called Encoder-Decoder Attention Block.
This attention block will respect each other and this is where the mapping from English to French words happens. The output of this block is attention vectors for each word in English and French sentences, where each vector representing the relation with other words in both languages.

Now we pass each attention vector into a feed-forward unit, it will make the output vectors form into something which is easily acceptable by decoder block or a linear block.
As the purpose of the decoder is to predict the following word, the output sizes of this feed-forward layer are the number of French words in the vocabulary. Softmax transforms the output into a word corresponding to the highest probability of the next word.
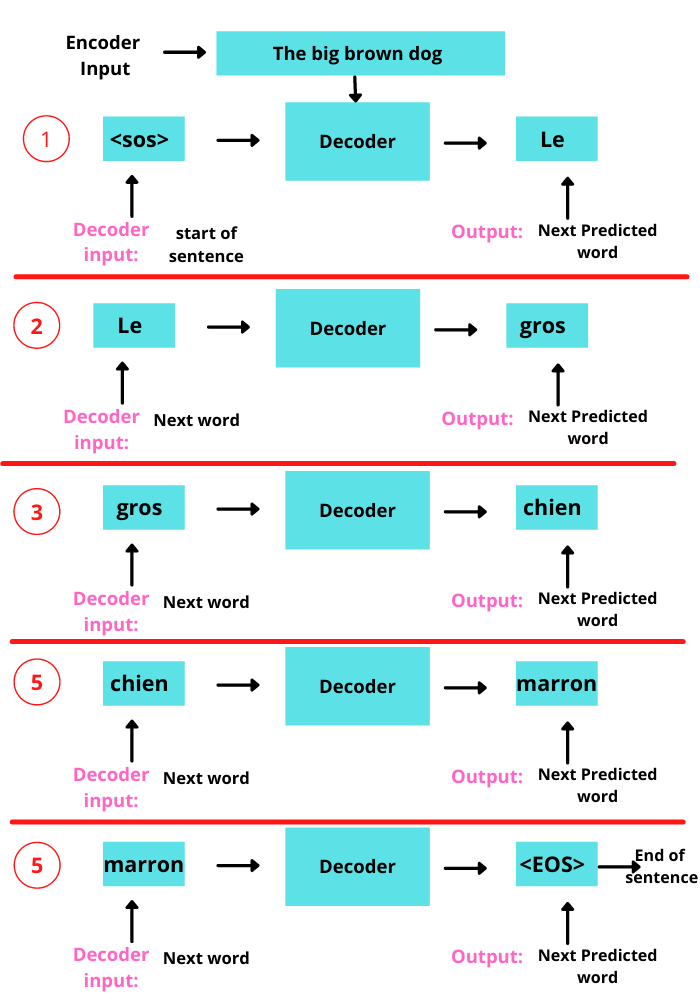
For each word generated, we repeat this process, including the French word, and used it to generate the next until the end of the sentence token generated.
So, this is how the Transformer works, and it is now the state-of-the-art technique in NLP. It is giving wonderful results, using a self-attention mechanism, and also solves the parallelization issue. Even Google uses BERT that uses a transformer to pre-train models for common NLP applications.
