Dimensionality Reduction — Feature Selection and Feature Extraction

Dimensionality reduction is the process of reducing the number of variables/features. It reduces the model complexity and overfitting.
It is further divided into two subcategories:
- Feature Selection
- Feature Extraction
Feature Selection
Feature selection is the process of selecting a subset of relevant features or variables. It also Prevents learning from noise/irrelevant data, improves accuracy, and reduces training time.
Why Feature Selection? — To train a model, we collect huge quantities of data to help the machine learn better. But not all this data will be useful to us. Some classes or a part of the data may not contribute much to our model and can be dropped.
Feature Selection models are of two types:
- Supervised Models — It uses the output label class for feature selection.
- Unsupervised Models — It does not need the output label class of feature selection.
In supervised models, we have 3 subcategories. There are:
- Wrapper Method
- Filter Method
- Embedded Method
Wrapper Method:
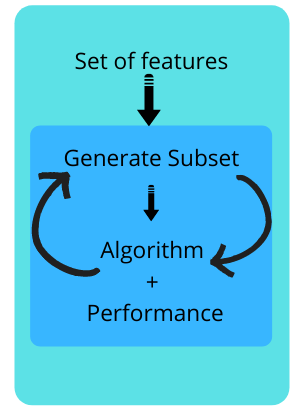
The selection of features is done by considering it as a search problem, in which different combinations are made, evaluated, and compared with other combinations.
— Split our data into subsets and train a model.
— Based on the output of the model, we add and subtract the features and train the model again.
— It forms the subsets using a greedy approach and evaluates the accuracy of all the possible combinations of features.
The wrapper methods usually result in better predictive accuracy than filter methods. But it is computationally more expensive.

Some Wrapper Method techniques are listed below:
- Forward Selection — Forward selection is an iterative process, which begins with an empty set of features. After each iteration, it keeps adding on a feature and evaluates the performance to check whether it is improving the performance or not. The process continues until the addition of a new variable/feature does not improve the performance of the model.
- Backward Elimination — Backward elimination is also an iterative approach, but it is the opposite of forward selection. This technique begins the process by considering all the features and removes the least significant feature. This elimination process continues until removing the features does not improve the performance of the model.
- Bi-directional Elimination —This method uses both forward selection and backward elimination technique simultaneously to reach to one unique solution.
- Exhaustive Selection —This technique is considered as the brute force approach for the evaluation of feature subsets. It creates all possible subsets and builds a learning algorithm for each subset and selects the subset whose model’s performance is best.
- Recursive Elimination — Recursive feature elimination is a recursive greedy optimization approach, where features are selected by recursively taking a smaller and smaller subset of features. Now, an estimator is trained with each set of features, and the importance of each feature is determined using coef_attribute or through a feature_importances_attribute.
Filter Method:
Features are selected on the basis of statistics measures. In other words, Features are dropped based on their relation to the output or how they are correlating to the output.
This method does not depend on the learning algorithm and chooses the features as a pre-processing step. And It filters out the irrelevant feature and redundant columns from the model by using different metrics through ranking.
It needs low computational time and does not overfit the data.

Some common techniques of filter methods are as follows:
- Information Gain — Information gain determines the reduction in entropy while transforming the dataset. It can be used as a feature selection technique by calculating the information gain of each variable with respect to the target variable.
- Chi-Square Test — Chi-square test is a technique to determine the relationship between the categorical variables. The chi-square value is calculated between each feature and the target variable, and the desired number of features with the best chi-square value is selected.
- Fisher’s Score — Fisher’s score is one of the popular supervised technique of features selection. It returns the rank of the variable on the fisher’s criteria in descending order. Then we can select the variables with a large fisher’s score.
- Missing Value Ratio — The value of the missing value ratio can be used for evaluating the feature set against the threshold value. The formula for obtaining the missing value ratio is the number of missing values in each column divided by the total number of observations. The variable is having more than the threshold value can be dropped.
- Correlation Coefficient —The correlation coefficient is a statistical measure of the strength of the relationship between the relative movements of two variables. The values range between -1.0 and 1.0. The logic behind using correlation for feature selection is that the good variables are highly correlated with the target. Furthermore, variables should be correlated with the target but should be uncorrelated among themselves.
- Variance Threshold — The variance threshold is a simple baseline approach to feature selection. It removes all features which variance doesn’t meet some threshold. By default, it removes all zero-variance features, i.e., features that have the same value in all samples. We assume that features with a higher variance may contain more useful information, but note that we are not taking the relationship between feature variables or feature and target variables into account, which is one of the drawbacks of filter methods.
- Mean Absolute Difference — This method is similar to variance threshold method but the difference is there is no square in MAD. This method calculates the mean absolute difference from the mean value.
- Dispersion Ratio — Dispersion ratio is defined as the ratio of the Arithmetic mean (AM) to that of Geometric mean (GM) for a given feature. Its value ranges from +1 to ∞ as AM ≥ GM for a given feature. Higher dispersion ratio implies a more relevant feature.
Embedded Method/Intrinsic Method:
Combined the quality of both filter and wrapper methods to create the best subset. This method takes care of the machine training iterative process while maintaining the computation cost to be minimum.
It is a Fast Processing method similar to the filter method but more accurate than the filter method.
Some Embedded Method Techniques are:
- Regularization — Regularization adds a penalty term to different parameters of the machine learning model for avoiding overfitting in the model. This penalty term is added to the coefficients; hence it shrinks some coefficients to zero. Those features with zero coefficients can be removed from the dataset. The types of regularization techniques are L1 Regularization (Lasso Regularization) or Elastic Nets (L1 and L2 regularization).
- Random Forest Importance — Different tree-based methods of feature selection help us with feature importance to provide a way of selecting features. Here, feature importance specifies which feature has more importance in model building or has a great impact on the target variable. Random Forest is such a tree-based method, which is a type of bagging algorithm that aggregates a different number of decision trees. It automatically ranks the nodes by their performance or decrease in the impurity (Gini impurity) over all the trees. Nodes are arranged as per the impurity values, and thus it allows to pruning of trees below a specific node. The remaining nodes create a subset of the most important features.
How to choose a Feature Selection Model?
For machine learning engineers, it is very important to understand which feature selection method will work properly for their model.
In machine learning, variables are of mainly two types:
- Numerical Variables: Variable with continuous values such as integer, float
- Categorical Variables: Variables with categorical values such as Boolean, ordinal, and nominals.

Feature Extraction
Feature extraction aims to reduce the number of features in a dataset by creating new features from the existing ones(and discarding the original features).
The primary goal of feature extraction is to compress the data with the goal of maintaining most of the relevant information.
Feature Extraction is used for improves accuracy, reduce the overfitting risk, speed up the training, and improved data visualization.
Types of Feature extraction Techniques:
- PCA — Principal Component Analysis
- LDA — Linear Discriminant Analysis as a supervised dimensionality reduction technique for maximizing class separability
- KPCA — Kernel Principal Component Analysis method can deal with the nonlinear relationship between variables as a multi-variable statistical process monitoring effective algorithm using this method to establish a multiple-status fault detection model.
